你的位置:开云官网切尔西赞助商(2025已更新(最新/官方/入口) > 新闻动态 > 开yun体育网在绽开域视觉一语气方面成果显赫-开云官网切尔西赞助商(2025已更新(最新/官方/入口)
发布日期:2025-11-15 14:38 点击次数:98
当今 AI 皆懂文物懂历史了开yun体育网。
一项来自北京大学的最新商榷激发柔和:他们推出了各人首个面向古希腊陶罐的 3D 视觉问答数据集——VaseVQA-3D,并配套推出了专用视觉言语模子VaseVLM。
这意味着,AI 正在从"识图机器"迈向"文化考古 Agent "。

传统视觉言语模子(VLM)如 GPT-4V、Gemini 等,擅长面容平淡图像,在绽开域视觉一语气方面成果显赫,但在面临文化遗产类复杂对象时——它们真实"迷茫若失"。受限于纯属数据的规模诡秘和语义建模才能,其对复杂纹饰、器形及文化布景的一语气仍存在彰着不及。
为什么?因为枯竭高质地、结构化的专科数据。
这次,北大牵头团队带来了残害性处罚决策。
AI 初次"看懂"古希腊陶罐
以往的视觉言语模子(VLM)如 CLIP、LLaVA、GPT-4V 等,诚然能识别平淡图片,却在文化遗产这类专科规模失灵。
北大团队指出:" AI 能认猫狗,却认不出陶罐的期间、作风与技法。"
于是他们构建了一个庞大的新基座 VaseVQA-3D。

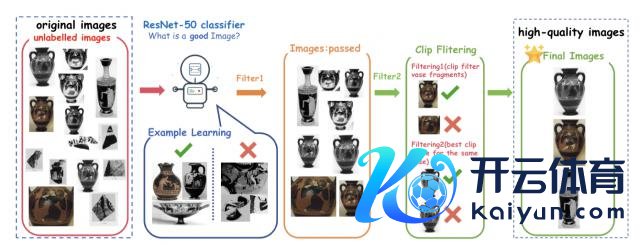
从现存资源里找了 3 万多张古希腊陶器的 2D 相片,先通过:
ResNet-50 质检:去掉迟滞与残败图像;
CLIP 语义过滤:识别"碎屑"与"完满器物";
多视角选优:自动挑选最好视角图像。三谈筛选,留住 3880 张高质地的;
再用 TripoSG 时候把这些 2D 图转成 664 个高保果真 GLB 模子(像果真陶器相同能看前后转折);
临了还通过 GPT-4o 生成问答与增强面容,配了 4460 组「问题 - 谜底」(比如 "这个陶器的制作工艺是什么?""是黑绘工艺"),甚而给每个 3D 模子写了谛视阐明。
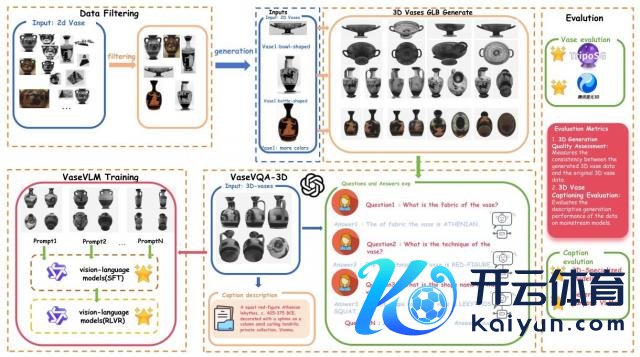
为了保证 3D 模子质地,脱落挑了 24 个高质地 3D 陶器当法度样板,用来考试生成的 3D 模子好不好。
追念下来即是:
664 个高保真 3D 古希腊陶罐模子(GLB 行径)
4460 条考古问答数据
完满的 2D → 3D 生成与质检历程
涵盖陶罐六大中枢属性:材质、工艺、形制、年代、胁制、包摄
VaseVLM:懂考古的视觉言语大模子
有了数据,团队进一步纯属了专用模子 VaseVLM。
以 Qwen2.5-VL 为基底,通过两阶段强化:
阶段一:SFT 监督微调 —— 用 360 ° 旋转视频 + 考古面容纯属基础识别才能
阶段二:RLVR 强化学习 —— 将考古学问拆分为六个语义维度(Fabric、Technique、Shape、Dating、Decoration、Attribution),AI 会每个维度凭证恢复获得奖励。
这种"可考证奖励机制"让模子的恢复更专科、更靠近学术法度。
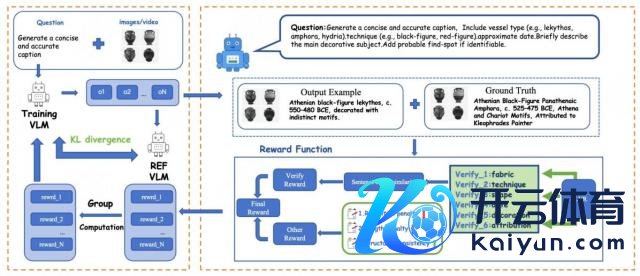
RLVR 奖励机制:AI 像考古学家相同分维度分析陶罐特征
在多项 Vase-3D 视觉问答任务上,VaseVLM 的发达大幅卓绝现存模子。
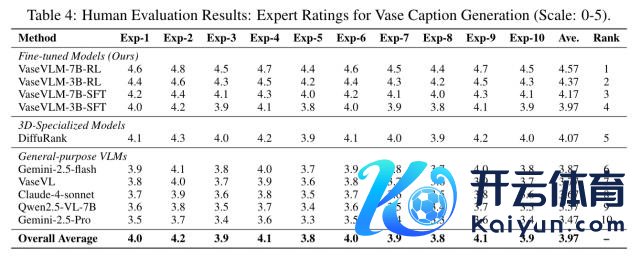
比较最强基线模子,VaseVLM 在 R@1 准确率擢升 12.8%;词汇相似度擢升 6.6%;各人东谈主工评分平均达 4.57/5(10 位考古各人评分)。
VaseVLM 生成的面容更当然、学术准确,显赫优于通用大模子。
改日,该样子探讨拓展到更多文化遗产规模,并树立更完善的数字遗产展示风景,为数字考古提供全新时候旅途。
论文原文:https://arxiv.org/abs/2510.04479
官方网站: https://aigeeksgroup.github.io/VaseVQA-3D
代码开源: https://github.com/AIGeeksGroup/VaseVQA-3D
数据集:https://huggingface.co/datasets/AIGeeksGroup/VaseVQA-3D
一键三连「点赞」「转发」「戒备心」
接待在辩驳区留住你的念念法!
— 完 —
咱们正在招聘又名眼疾手快、柔和 AI 的学术剪辑实习生 � �
感深嗜的小伙伴接待柔和 � � 了解确定

� � 点亮星标 � �
科技前沿进展逐日见开yun体育网
Powered by 开云官网切尔西赞助商(2025已更新(最新/官方/入口) @2013-2022 RSS地图 HTML地图